Datenstrukturen im Jitterbit Integration Studio
Einführung
Datenstrukturen können während der Aktivitätskonfiguration als Schemata bereitgestellt werden oder sie können innerhalb der Transformation definiert werden selbst. Wenn in einer Aktivität Datenstrukturen bereitgestellt werden, werden die Schemata von der Transformation übernommen, wobei die Aktivität als Quelle oder Ziel in der Operation verwendet wird. Sobald die Quell- und Zielschemata einer Transformation definiert sind, erstellen Sie Transformation zwischen den Quell- und Zielschemata, um zu definieren, wie die Daten verarbeitet werden sollen.
Informationen zum Beheben bestimmter Fehler bei der Ausführung von Operation, die durch Datenstrukturen verursacht werden, finden Sie unter Fehlerbehebung bei Operationen.
Datenstrukturtypen
In Harmony können Quell- und Zielschemata Datenstrukturen verwenden, die entweder als flach oder hierarchisch.
Flache Struktur
Eine flache Datenstruktur besteht aus einem oder mehreren einzelnen Feldern und Datensätzen in einer zweidimensionalen Struktur. Beispiele hierfür sind CSV-Dateien, einfache XML-Dateien und einzelne Datenbanktabellen. Eine flache Datenstruktur wird auch als „Flat File“-Struktur bezeichnet.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</customer>
Hierarchische Struktur
Eine hierarchische Datenstruktur weist eine oder mehrere übergeordnete oder verschachtelte Beziehungen zwischen Feldern und Datensätzen in einer komplexen Struktur auf. Eine hierarchische Datenstruktur wird manchmal als relationale, mehrstufige, komplexe Daten- oder Baumstruktur bezeichnet.
<customer>
<id>10123</id>
<name>ABC Co.</name>
<addresses>
<address>
<street>1 Main St.</street>
<city>Anytown</city>
<state>NY</state>
<zip>12345</zip>
</address>
<address>
<street>1 Time Square</street>
<city>New York City</city>
<state>NY</state>
<zip>54321</zip>
</address>
</addresses>
</customer>
Anzeige von Datenstrukturen
Datenstrukturen werden in einem Baumformat angezeigt, das sich erweitern und reduzieren lässt, um entweder den gesamten Baum oder nur einen Teil davon anzuzeigen.
Jeder Baum besteht aus Knoten und Feldern, wobei Felder innerhalb der Quelldatenstruktur Feldern innerhalb der Zieldatenstruktur zugeordnet werden können.
Knoten haben links neben dem Knotennamen ein Dreiecksymbol, mit dem sie ein- und ausgeblendet werden können. Standardmäßig werden Knoten bei Schemata mit maximal 750 Knoten bis zu 8 Ebenen und bei Schemata mit mehr als 750 Knoten bis zu 5 Ebenen ausgeblendet. Alle Knoten unterhalb eines Zielknotens können gleichzeitig über die Aktionsmenü „Alle Knoten unterhalb dieses Knotens ausblenden“ im Schema ausgeblendet werden (siehe Zielknoten im Mapping-Modus). Wenn Sie Knoten erweitern oder reduzieren, merkt sich Integration Studio den zuletzt verwendeten Erweiterungsstatus, wenn Sie das nächste Mal auf die Transformation zugreifen.
Nach dem Erweitern werden in Knoten alle enthaltenen untergeordneten Knoten und Felder angezeigt. Knoten können als Ordner betrachtet werden, deren untergeordnete Knoten Unterordner sind. Felder sind in Knoten enthalten und werden mit ihrem Datentyp aufgelistet (boolean, integer, double, binary, string).
Beispielsweise ist in der unten gezeigten Zielstruktur der Knoten json schließt den untergeordneten Knoten ein item, das die Felder enthält employeeId, name, Und title Der Knoten item enthält auch den untergeordneten Knoten employeeDetails, das die Felder enthält salary, isWorking, Und status.
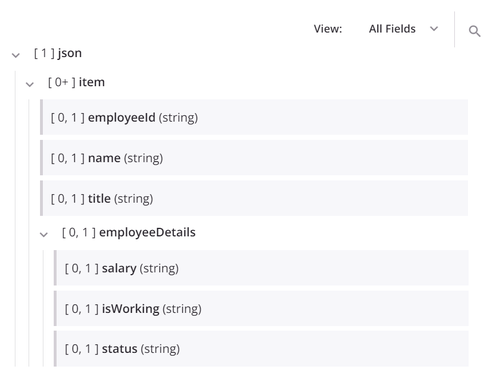
Anzeige der zugeordneten Felder
Ein Transformation besteht aus Zielfeldern oder -knoten und den zugehörigen Scripts. Diese Scripts können Verweise auf Quellfelder oder -knoten oder Projektkomponenten enthalten, Funktionen verwenden oder andere gültige Script verwenden. Ein Mapping umfasst keine Zielfelder, die nicht gemappt sind.
Wenn Quellobjekte und Variablen im Zielfeld definiert sind, werden sie als Blöcke innerhalb des Zielfelds angezeigt. Das zugeordnete Zielfeld wird mit einer violetten vertikalen Linie links neben dem Zielfeldblock angezeigt:

Wenn Sie sich im Zuordnungsmodus befinden und sowohl ein Quell- als auch ein Schema auf dem Bildschirm sichtbar sind, zeigt eine visuelle hellgraue Linie die Verbindung mit dem Quellobjekt an, wenn Sie mit der Maus über ein Quell- oder Zielfeld fahren.
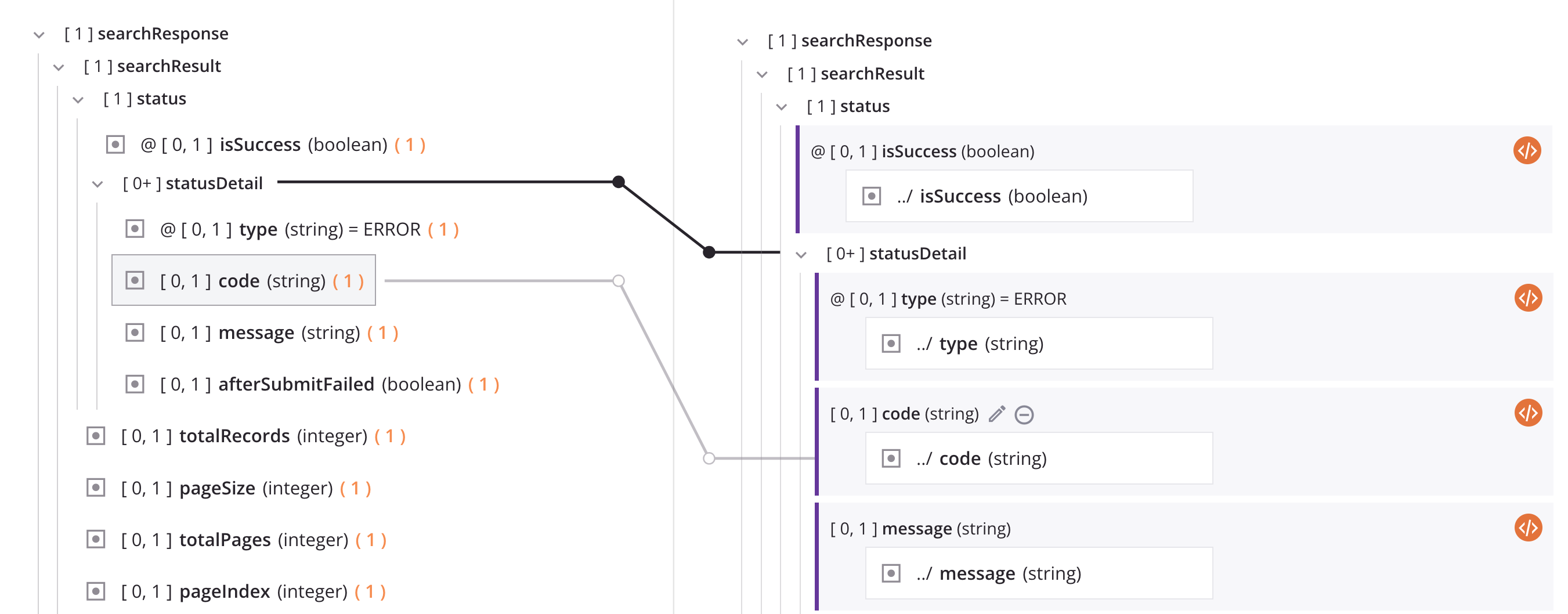
Die durchgezogene schwarze Linie im obigen Bild wird im nächsten Abschnitt Schleifenknoten erläutert.
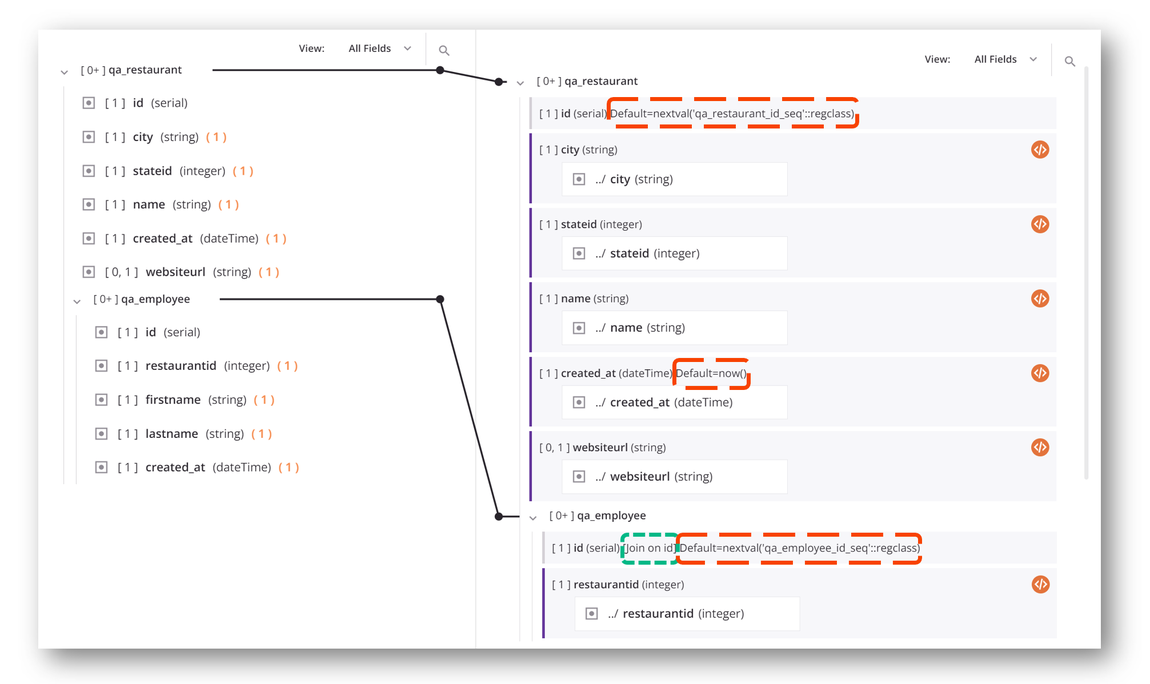
Die Zielseite des Mappings zeigt auch an, ob ein Feld Standardwerte (im Bild unten rot umrandet) oder Verknüpfungen (im Bild unten grün umrandet) hat. Beispielsweise fügt diese Transformation Daten in eine Datenbank ein, deren id Felder werden automatisch inkrementiert und deren created_at Feld ist standardmäßig auf die aktuelle Zeit eingestellt. Es zeigt auch, dass die untergeordnete Tabelle qa_employee wurde über das ID-Feld mit der übergeordneten Tabelle verknüpft qa_restaurant:
Wenn ein reduzierter Knoten Zielfeldzuordnungen enthält, wird dieser fett dargestellt, um darauf hinzuweisen, dass er Zuordnungen enthält:

Schleifenknoten
Ein Loop-Knoten ist ein Quell- oder Zielknoten mit sich wiederholenden Datenwerten, wie etwa Einzelposten in einer Rechnung oder einer Reihe von Kundendatensätzen.
Beim Zuordnen von Schleifenknotenfeldern wird automatisch eine durchgezogene schwarze Iteratorlinie angezeigt. Diese zeigt an, dass der Transformation den Quelldatensatz durchläuft. Die Position der generierten Iteratorlinien hängt von der Anzahl der entsprechenden Quellschleifenknoten ab.
Eine Transformation kann keine oder mehrere Iteratorzeilen haben. Wenn mehrere Iteratorzeilen vorhanden sind, wird in der Zielstruktur von oben nach unten vorgegangen.
Um die Anzeige einer einzelnen Iteratorlinie umzuschalten, klicken Sie direkt auf die Kreisform, die dem Zielknoten am nächsten ist:
![]()
Die einzelne Schleifenknotenlinie wird dann zu einem orangefarbenen Stumpf, der bei erneutem Anklicken die vollständige Linie anzeigt:
Beispiel
Als Beispiel für eine Schleifenknotenzuordnung betrachten Sie die folgende hierarchische Quellstruktur mit einem Quellknoten der obersten Ebene (item) mit Feldern, die Informationen über ein Unternehmen liefern. Ein untergeordneter Quellknoten, locationDetails, enthält ein Array (json$item.locationDetails$item.) von Objekten mit Feldern für mehrere Filialstandorte innerhalb eines Unternehmens. Sowohl der übergeordnete als auch der untergeordnete Knoten gelten als Schleifenknoten, da die Daten mehrere Unternehmensdatensätze mit jeweils mehreren Filialstandortdatensätzen enthalten können.
Beachten Sie nun, dass diese Daten einer flachen Zielstruktur zugeordnet werden, wodurch für jeden Filialstandort ein Datensatz entsteht. Beim Zuordnen der Felder wird automatisch eine Iteratorlinie angezeigt, die Quell- und Zielschleifenknoten verbindet. Diese Linie gibt an, dass das Ziel so oft eine Schleife durchläuft, wie sich wiederholende Datensätze in der Quelle vorhanden sind. In diesem Beispiel durchläuft das Ziel jeden Filialstandortdatensatz für jedes Unternehmen.

Mapping von einer Quelle mit mehreren Instanzen zu einem Ziel mit einer einzigen Instanz
Wenn der generierte Ziel-Schleifenknoten von mehr als einem Quellschleifenknoten abhängt, müssen Sie möglicherweise eine Nichtübereinstimmung der Vorkommen mit der Zuordnung beheben.
Wenn die Quelldatenstruktur ein Array mit mehreren Objekten ist und einer Zieldatenstruktur mit einem einzelnen Objekt zugeordnet wird, wird dieser Dialog angezeigt:

Um die erste Instanz der Quelle im Mapping zu verwenden, wählen Sie Ja, um automatisch ein Raute-Symbol einzufügen. (#) im Referenzpfad des Datenelements. Dies bedeutet, dass nur der erste Datensatz zugeordnet wird. Beispielsweise wird bei der folgenden Zuordnung nur der erste Kundendatensatz im Array der Zielstruktur zugeordnet, die nur einen einzigen Kunden enthält. Beachten Sie, dass jedes zugeordnete Zielfeld nun ein Script enthält, wie durch die Script.

Wenn Sie für ein beliebiges zugeordnetes Feld in den Script wechseln, sehen Sie, dass ein #1 Im Pfad des zugeordneten Quellobjekts wurde ein Attribut hinzugefügt, um anzuzeigen, dass die erste Instanz zugeordnet ist.

Wenn Sie nicht möchten, dass die erste Instanz der Quelle verwendet wird, können Sie mithilfe der instanzauflösenden Funktionen eine andere Logik festlegen (siehe Instanzfunktionen).
Datennormalisierung
Wenn Sie Daten von einer flachen Struktur auf eine hierarchische Struktur abbilden, müssen die Daten möglicherweise vor der Transformation normalisiert werden.
Standardmäßig verwendet Harmony einen Normalisierungsalgorithmus zum Erstellen des Zielbaums. Dadurch wird die flache Struktur der Quelle in eine hierarchische Quellstruktur umgewandelt, die dann der hierarchischen Zielstruktur zugeordnet werden kann.
In der Zielstruktur werden das Stammelement und alle Mehrfachinstanzelemente unter dem Stammelement verwendet, um die Struktur der sekundären Quellelemente zu erstellen. Die Attribute (oder Felder) dieser sekundären Quellelemente sind flache Datenelemente, die dann in den Zuordnungen des entsprechenden Zielelements verwendet werden.
Wenn die Quellstruktur richtig definiert ist, wird der Normalisierungsprozess vereinfacht, indem Knoten mit denselben übergeordneten Knoten kombiniert werden.
Zur Normalisierung stehen drei Optionen zur Verfügung:
- Vollständige Normalisierung: Alle Elemente mit demselben übergeordneten Element und alle Felder werden auf ein Element reduziert. (Dies ist die Standardeinstellung.)
- Partielle Normalisierung: Dasselbe wie vollständige Normalisierung, außer dass die niedrigsten untergeordneten Elemente nicht normalisiert werden.
- Keine Normalisierung: Jeder flache Datensatz erstellt einen Zweig von Elementen; beim Erstellen der hierarchischen Quellstruktur wird keine Reduzierung der Elemente durchgeführt.
Die hierarchische Struktur kann einen einzelnen Instanzknoten enthalten. In diesem Fall wird nur das erste Element dieser Wurzel beibehalten. Flat Records, die mit diesem Wurzeldatenknoten in Konflikt stehen, werden ignoriert.
Um die Normalisierung zu deaktivieren, setzen Sie die Variable Jitterbit jitterbit.transformation.disable_normalization Zu true (siehe Transformation Jitterbit-Variablen).
Instanz- und Mehrfachzuordnung
Transformation ist der Prozess, der die Beziehung zwischen Dateneingaben und der resultierenden Datenausgabe definiert. Je nach verwendeten Datenstrukturtypen kann das Transformation als Instanzmapping oder Mehrfachmapping bezeichnet werden.
Instanzzuordnung
Instanzmapping beschreibt die Abhängigkeit der Zuordnung einer Zielinstanz von möglicherweise mehreren Instanzen einer Quelle. Instanzmapping kann entweder flach-zu-flach (Eins-zu-eins) oder hierarchisch-zu-flach (Viele-zu-eins) erfolgen.
Mehrfachzuordnung
Multiple Mapping beschreibt die Abbildung zweier hierarchischer Datenstrukturen oder die Abbildung einer einzelnen, flachen Struktur, die hierarchisch aufgebaut ist und deren untere Segmente mehrere Wertesätze, wie z. B. Name/Wert-Paare, enthalten. Multiples Mapping kann entweder hierarchisch-hierarchisch (Viele-zu-Viele) oder flach-hierarchisch (Eins-zu-Viele) erfolgen.
Beispiele
Beispielsituationen für Instanz- und Mehrfachzuordnungen finden Sie in der Design Studio-Dokumentation:
- Instanzzuordnung
- Mehrfachzuordnung
Obwohl diese Beispiele für Design Studio gelten, können dieselben Konzepte auch im Integration Studio angewendet werden.
Praktische Schulungsmodule mit Beispielen zum Mapping einfacher und komplexer Datenbank-, Text- und XML-Dateien finden Sie unter Einführung in Jitterbit Integration Studio.